Содержание
Фраза «у меня работает» редко описывает реальную работоспособность продукта. Обычно она означает, что приложение запускается в одной среде и ломается в другой, а процесс выкладки на сервер не воспроизводим. В результате часть времени уходит не на исправление дефекта, а на выяснение того, какая именно версия кода и зависимостей оказалась на продакшене, какие переменные окружения были выставлены и какие команды запускались «вручную».
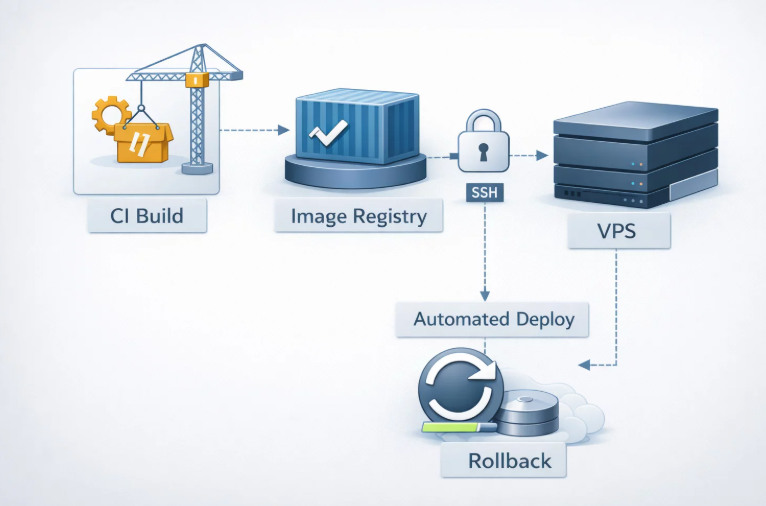
Типовой источник таких историй – ручное копирование файлов на виртуальный сервер (VPS/VDS), запуск сборки прямо на сервере, правки конфигурации «по месту», отсутствие единого артефакта релиза и журнала изменений. Ниже разобран практический сценарий, который закрывает именно эту проблему: сборка в CI и автоматический деплой на собственный сервер без ручных переносов, с возможностью проверки и отката.
Когда «у меня работает» становится инцидентом
Ручной деплой на VPS обычно выглядит так: архив или директория с проектом копируется по SFTP/rsync, затем на сервере выполняются команды «на память» (установка зависимостей, миграции, перезапуск сервисов). На каждом шаге возможны расхождения, которые не видны в момент выкладки:
- Дрейф окружения – разные версии Node.js/Python/PHP/Java, системных библиотек, утилит сборки, расширений
- Непредсказуемые зависимости – отсутствие lock-файлов или их игнорирование приводит к установке «свежих» версий пакетов
- Смешивание релизов – частичное копирование директории оставляет старые файлы рядом с новыми
- Секреты и конфиги «внутри проекта» – случайная передача .env в репозиторий или копирование «чужих» конфигураций на сервер
- Отсутствие трассируемости – непонятно, какой коммит и какой набор параметров сейчас в продакшене
- Человеческий фактор – забытый флаг, пропущенный шаг, перезапуск не того сервиса
В подобных сценариях неделя легко уходит на реконструкцию состояния сервера и воспроизведение «той самой» сборки. Единственный устойчивый способ убрать спор – сделать так, чтобы сервер получал строго определенный артефакт релиза, а все операции деплоя выполнялись одинаково при каждом запуске.
Что именно должно дать автоматизация
Сборка и деплой «без ручных копирований» – не про скорость нажатия кнопок. Это про свойства процесса, которые защищают от расхождений сред:
- Единый артефакт – бинарник, архив или контейнерный образ, построенный один раз и разворачиваемый в неизменном виде
- Повторяемость – сборка одинаково проходит на любом агенте CI, а деплой выполняется одним и тем же скриптом
- Версионирование – артефакт привязан к коммиту (SHA) или тегу релиза
- Прозрачность – логи сборки и деплоя сохраняются в CI, шаги формализованы
- Откат – возврат на предыдущую версию занимает минуты, а не часы
- Минимальные привилегии – CI имеет ровно тот доступ, который нужен для выкладки, без лишних прав
Эти свойства реализуются разными способами. Дальше – краткий разбор вариантов и затем референсная схема для VPS/VDS, которая чаще всего дает предсказуемый результат.
Три рабочих модели деплоя на VPS/VDS
Вариант 1. «Git pull» на сервере
Суть: сервер подключается к репозиторию и забирает код командой git pull, после чего запускается сборка/перезапуск.
Плюсы: минимальная инфраструктура, быстро стартовать.
Минусы: сборка и зависимости зависят от состояния сервера; сложно гарантировать, что на сервере стоит нужная версия рантайма; выше риск «поправить руками» и забыть; откат требует аккуратного управления ветками/тегами и повторных сборок.
Когда уместно: прототипы и проекты без строгих требований к воспроизводимости.
Вариант 2. Сборка артефакта в CI и загрузка на сервер
Суть: CI собирает архив (например, фронтенд build или бинарник), затем загружает на сервер по SSH (scp/rsync), переключает симлинк на новый релиз и перезапускает процесс через systemd.
Плюсы: артефакт фиксирован; сервер не выполняет тяжелую сборку; удобно для статических сайтов, Go/Java/.NET.
Минусы: для приложений с большим числом зависимостей сложнее обеспечить совпадение системных библиотек; часто появляется «зоопарк» скриптов под разные типы проектов.
Когда уместно: сервисы без контейнеризации или когда контейнеры запрещены политикой.
Вариант 3. Контейнерный образ собирается в CI, сервер только запускает
Суть: CI собирает Docker-образ, публикует его в registry, затем сервер делает docker pull и перезапускает сервис через Docker Compose (или оркестратор).
Плюсы: высокая воспроизводимость; одинаковый рантайм на dev/CI/prod; простая трассируемость по тегу образа; удобный откат на предыдущий тег.
Минусы: нужен Docker на VPS; требуется дисциплина по секретам и хранению образов; для тяжелых образов важно продумать размер и кэширование.
Когда уместно: большинство веб‑приложений и API на VPS/VDS, где требуется стабильный релизный процесс.
Дальше рассматривается именно третий вариант – как самый надежный для устранения «у меня работает» в реальных внедрениях на виртуальных серверах.
Референсный сценарий: CI собирает образ, VPS деплоится через SSH и Docker Compose
Идея – разделить ответственность: CI отвечает за сборку и тесты, сервер отвечает за запуск и маршрутизацию трафика. В результате на сервер перестают попадать «полусобранные» состояния, а ручное копирование файлов заменяется на формализованный деплой одной командой из CI.
Базовая схема:
- Коммит попадает в основную ветку репозитория
- CI выполняет тесты, собирает контейнерный образ и пушит его в registry с тегом коммита
- CI по SSH подключается к VPS/VDS и запускает короткий деплой‑скрипт: docker login → docker pull → docker compose up -d
- После перезапуска выполняется проверка health endpoint; при проблеме выполняется откат на предыдущий тег
В качестве площадки подходит любой провайдер, где доступна аренда VPS/VDS с публичным IP, SSH‑доступом и возможностью установить Docker. В некоторых проектах требуется минимальная задержка до российских пользователей и интеграций – тогда выбираются площадки с размещением в Москве, например VPS.house (как один из множетсва примеров сервиса аренды виртуальных серверов).
Шаг 1. Подготовка виртуального сервера
Пример ниже ориентирован на Ubuntu 22.04 LTS или Debian 12. На других дистрибутивах меняются названия пакетов и команды управления сервисами, но логика остается прежней.
Минимальные действия перед подключением CI:
- обновление системы и включение автоматических security‑обновлений (по политике проекта)
- создание отдельного пользователя для деплоя (не root)
- настройка SSH только по ключам; отключение password‑логина при возможности
- базовый firewall (например, UFW) с открытыми портами 22/80/443
- установка Docker и Compose plugin
- создание каталога проекта, где будет лежать docker-compose.yml и env‑файлы
Пример команд (адаптировать под конкретную ОС):
sudo apt update && sudo apt upgrade -y
sudo adduser deploy
sudo usermod -aG sudo deploy
sudo mkdir -p /opt/app
sudo chown deploy:deploy /opt/app
sudo ufw allow OpenSSH
sudo ufw allow 80/tcp
sudo ufw allow 443/tcp
sudo ufw enable
Пользователь deploy получает права на обслуживание приложения, но не используется для интерактивной работы «на продакшене». Это снижает вероятность случайных правок и упрощает аудит.
Шаг 2. Установка Docker и настройка прав
Для продакшен‑сценариев предпочтительнее установка Docker из официального репозитория, чтобы получать предсказуемые версии и обновления. После установки пользователь deploy добавляется в группу docker (или деплой выполняется через sudo, если политика безопасности требует запретить доступ к docker‑сокету).
Критический момент безопасности: доступ к docker‑сокету по факту равен root‑доступу. Если проект требует строгого разграничения, деплой выполняется через sudo с ограниченным набором команд или через отдельный механизм (например, pull‑модель с agent/runner на сервере).
Шаг 3. Reverse proxy и TLS
На VPS/VDS чаще всего используется Nginx в роли reverse proxy: он принимает HTTPS, отдает статические файлы (при наличии) и проксирует запросы в контейнер приложения. TLS‑сертификаты обычно выдаются через ACME (например, certbot). Для деплоя это важно по двум причинам:
- проверка работоспособности после релиза должна выполняться по тому же домену и протоколу, что и пользовательский трафик
- обновление контейнера не должно ломать сетевой контур и правила firewall
В простейшей конфигурации контейнер приложения слушает внутренний порт (например, 3000), а Nginx – 443 на хосте и проксирует внутрь.
Шаг 4. Секреты и конфигурация: где хранить переменные
Причина многих «у меня работает» – разные переменные окружения и конфиги. В схеме с Docker Compose удобен разделенный подход:
- .env с секретами хранится только на сервере (и в защищенном хранилище секретов, если оно есть); в репозиторий не попадает
- Тег образа передается отдельно (через переменную в CI) и не смешивается с секретами
На сервере создается файл, например /opt/app/app.env, который содержит только настройки окружения (строки вида KEY=VALUE). Этот файл подхватывается Docker Compose через env_file.
Шаг 5. SSH‑ключ для деплоя из CI
CI должен подключаться к VPS/VDS без пароля. Для этого создается отдельная пара ключей (ed25519. и добавляется в ~/.ssh/authorized_keys пользователя deploy. Приватный ключ хранится в секретах CI (GitHub Secrets / GitLab CI Variables) и не попадает в репозиторий.
Практические ограничения, которые часто забываются:
- ключ лучше ограничивать по source IP, если CI имеет фиксированные адреса (не всегда возможно)
- в authorized_keys допускается добавление опций (no-port-forwarding, no-agent-forwarding), если не требуется проксирование
- для деплоя обычно достаточно ограниченного набора команд, но принудительная команда (forced command) усложняет сценарии с миграциями и проверками
Шаг 6. docker-compose.yml: минимальный пример под деплой
В каталоге /opt/app размещается docker-compose.yml. Важно, чтобы образ ссылался на переменную тега – тогда деплой сводится к подстановке нового тега и перезапуску.
Пример (схематично):
services:
app:
image: ghcr.io/org/project:${APP_TAG}
env_file:
— ./app.env
restart: unless-stopped
ports:
— «127.0.0.1:3000:3000»
healthcheck:
test: [«CMD», «curl», «-fsS», «http://127.0.0.1:3000/health»]
interval: 10s
timeout: 3s
retries: 6
Контейнер пробрасывается только на localhost, чтобы внешняя поверхность атаки оставалась у Nginx. Healthcheck нужен для автоматизированной проверки после обновления.
Шаг 7. CI: сборка образа и деплой по SSH (пример на GitHub Actions)
Ниже – примерный workflow, который демонстрирует ключевую мысль: сборка происходит в CI, а сервер только тянет готовый образ и перезапускает сервис. Аналогичная логика реализуется в GitLab CI, Jenkins, TeamCity и других системах.
Пример .github/workflows/deploy.yml (схематично):
name: build-and-deploy
on:
push:
branches: [«main»]
jobs:
build:
runs-on: ubuntu-latest
steps:
— uses: actions/checkout@v4
— uses: docker/setup-buildx-action@v3
— name: Login to registry
run: echo «${REGISTRY_TOKEN}» | docker login ghcr.io -u «${REGISTRY_USER}» —password-stdin
— name: Build and push
run: |
TAG=${GITHUB_SHA}
docker build -t ghcr.io/org/project:${TAG} .
docker push ghcr.io/org/project:${TAG}
deploy:
needs: build
runs-on: ubuntu-latest
steps:
— name: Deploy via SSH
run: |
ssh -o StrictHostKeyChecking=no deploy@${SERVER_HOST} \
«cd /opt/app && export APP_TAG=${GITHUB_SHA} && docker compose pull && docker compose up -d»
В реальном проекте этот пример стоит дополнить как минимум:
- тестами перед сборкой и пушем образа
- логином в registry на сервере (один раз или на каждый деплой) – безопаснее через токен с минимальными правами
- выделенным деплой‑скриптом на сервере, чтобы команда SSH оставалась короткой и одинаковой
- проверкой здоровья после обновления и условным откатом
Шаг 8. Проверка после релиза и откат
Без проверки деплой превращается в «быстро сломать». Минимально достаточная практика – health endpoint и автоматический откат на предыдущий тег при неуспехе проверки.
Один из рабочих вариантов на VPS: хранить текущий и предыдущий тег в файле, например /opt/app/deploy.state. При успешном запуске новый тег становится текущим, при ошибке – выполняется возврат. Пример логики (псевдоскрипт):
deploy.sh (схема):
set -e
cd /opt/app
NEW_TAG=«$1»
CURRENT_TAG=«$(cat ./current.tag 2>/dev/null || true)»
echo «$NEW_TAG» > ./current.tag
export APP_TAG=«$NEW_TAG»
docker compose pull
docker compose up -d
sleep 5
curl -fsS https://example.com/health
Если curl возвращает ошибку, скрипт завершится с ненулевым кодом. В таком случае в CI можно выполнить отдельную команду отката, которая вернет CURRENT_TAG и перезапустит Compose. Практика показывает, что даже такой «простой» откат экономит часы при неудачных релизах.
Отдельный нюанс: миграции базы данных. Если миграции несовместимы назад, откат «по образу» может не вернуть работоспособность. В критичных системах применяются совместимые миграции (expand/contract), либо вводится отдельный шаг «migrate» до переключения трафика.
Push или pull: два способа запускать деплой на собственном сервере
В примере выше используется push‑модель: CI подключается к серверу и инициирует обновление. Это популярный вариант, но у него есть ограничения (доступ по SSH снаружи, необходимость хранить ключ в CI).
Альтернатива – pull‑модель: на VPS/VDS работает агент (runner), который сам забирает задачу из CI и выполняет деплой локально. Преимущества – нет входящего SSH с «внешней стороны CI», проще ограничить сеть, удобнее интегрировать в закрытых контурах. Недостатки – на сервере появляется дополнительный компонент, который требуется обновлять и мониторить.
Выбор зависит от требований безопасности. Для публичных проектов с обычным периметром push‑модель через SSH остается наиболее простой в поддержке.
Минимальная гигиена безопасности для CI/CD на VPS
Автоматизация не должна превращать виртуальный сервер в «открытую дверь». В практических внедрениях полезно проверять следующие пункты:
- Отдельный пользователь для деплоя, без интерактивной работы под root
- SSH только по ключам, по возможности – ограничение AllowUsers и отключение password authentication
- Ограничение прав ключа в authorized_keys (опции запрета форвардинга) – если функциональность не нужна
- Раздельные секреты: токен registry с правом read/pull для сервера и отдельный токен с правом push для CI
- Логи: журнал SSH‑логинов, логи Nginx, docker logs или централизованный сбор
- Обновления: регулярные security‑апдейты ОС и Docker, плановый пересмотр версий образов
При выборе площадки под аренду VPS важно, чтобы сервер можно было быстро переустановить и восстановить «с нуля» по документации/скриптам. В этом смысле полезнее смотреть не на маркетинговые цифры, а на операционные возможности панели и сети – пример типовых требований обычно указывается на страницах провайдеров вроде VPS.house с возможностью аренды VPS в Москве, но конкретный выбор зависит от периметра задач, бюджета и требований к задержкам.
Что чаще всего ломает автоматический деплой (и как это лечится)
- Образ «плывет» от сборки к сборке. Решение: фиксировать версии базовых образов и зависимостей, использовать lock‑файлы, не собирать «latest» без контроля
- Секреты попадают в образ. Решение: передавать секреты через env_file/переменные на сервере, исключать .env через .dockerignore, не копировать секреты в Dockerfile
- Нет health endpoint. Решение: добавлять минимальный /health (без зависимости от внешних сервисов) и проверять его после перезапуска
- Конкурирующие деплои (два коммита подряд). Решение: включать блокировку на уровне CI (concurrency) или на уровне сервера (lock‑файл в deploy.sh)
- Миграции выполняются «между делом». Решение: формализовать шаг миграций и сделать его предсказуемым (отдельная команда/контейнер)
- Сервер превращается в «снежинку». Решение: документировать подготовку VPS или автоматизировать ее (Ansible/Terraform/скрипты), хранить конфигурацию инфраструктуры отдельно от приложения
Если Docker не подходит: короткая альтернатива без контейнеров
Иногда контейнеризация невозможна (наследуемая среда, ограничения политики, специфичное ПО). В этом случае задача «убрать ручные копирования» все равно решается, но артефактом становится архив или собранный каталог.
Рабочая минимальная схема:
- CI собирает артефакт (например, dist/ или бинарник), упаковывает в tar.gz и подписывает версию (коммит/тег)
- CI загружает артефакт на VPS по SSH в каталог releases/ (rsync/scp)
- На сервере переключается симлинк current → новый релиз
- systemd перезапускает сервис (или reload для Nginx/PHP-FPM)
- Проверяется /health и при проблеме симлинк возвращается на предыдущий релиз
По сравнению с контейнерами здесь выше риск несовпадения системных библиотек, поэтому особенно важно фиксировать версии рантайма и зависимостей и не «подкручивать» окружение на сервере вручную.
Чек‑лист: признак того, что «ручной деплой» действительно исчез
- На VPS/VDS не выполняется сборка приложения «вручную» – на сервер попадает готовый артефакт
- Любая выкладка привязана к коммиту/тегу и отражается в логах CI
- Переменные окружения и секреты находятся в управляемом месте и не копируются между средами случайно
- Откат выполняется за минуты и не требует реконструкции состояния
- Развертывание нового сервера (после сбоя или миграции) описано и воспроизводимо
После внедрения CI/CD на собственном виртуальном сервере исчезает сама почва для споров в стиле «у меня работает»: одинаковые сборки, одинаковые шаги деплоя и понятный контроль версий заменяют ручные копирования и «магические» команды. Для проектов на VPS/VDS это часто оказывается самым быстрым способом сократить потери времени на релизах без перехода на управляемые PaaS‑платформы.







